Overview
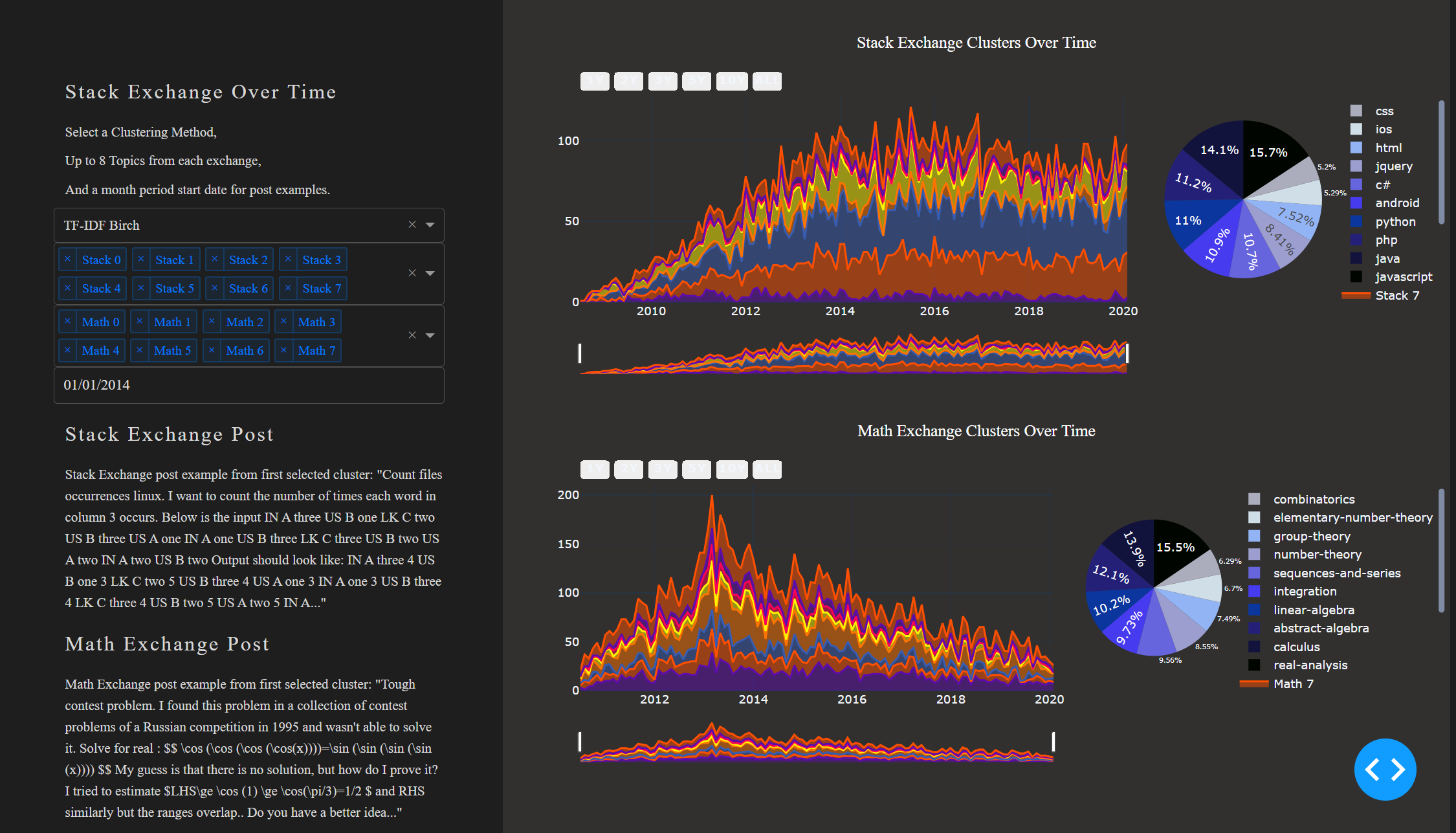
The project’s goal was to identify the patterns between mathematical and programming concepts present in math and stack exchange and dynamically represent them. The goal was to abstract mathematical and programming concepts from a document, namely the questions posed on math and stack exchange, and produce an embedding. From this embedding, several clustering techniques were used to separate the questions into eight distinct clusters representing the topics with minimal overlap. Once clustered, the concepts were analyzed over time, and correlations between time series were calculated. After identifying the most correlated topics between each question exchange, the delays between the signals were modeled using dynamic time warping. Through dynamic time warping, the delays in each time-series irregular delays can be effectively interpreted between the two topic signals.
Technical
The techniques used to model the documents were TF-IDF, Doc2Vec, and a document-based Bert variant. Once modeled, the document representation was clustered into eight categories using Birch clustering, K-means, and Agglomerative clustering. The trends were compared using dynamic time warping. The topics were also modeled separated using NNMF and LDA. The results were presented in a fully interactive dashboard using Dash and Plotly. This dashboard allowed the user to select time windows, the modeling used, and see example posts from the selected clusters.
{kind=link}